
This article is about Amazon Bedrock and its value proposition in the LLM arena. Using this tool, I tested different LLMs for a text classification task.
Why AWS has the upper hand on ML and AI on the cloud
At different times I tried the 3 main different cloud providers in a work setting. Each one has its own strengths. For example, Google BigQuery is great for SQL ETL and low code ML. But, I find that AWS is still the best for ML and AI.
They were the first on the market, to develop an end to end platform ML platform with SageMaker, that is capable of dealing with all the phases of a data science project. They definitely win for ease of use and variety of services.
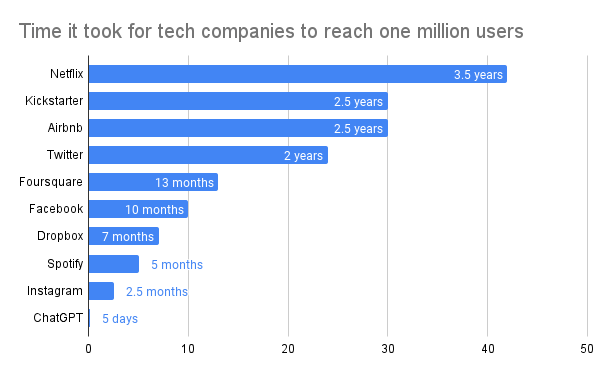
Furthermore, it’s impressive to see how quickly the landscape is changing. Many LLM developers entered the market in just under two years since widely available generative AI became available. This was when chatGPT became widely available (30th November 2022).
Now let’s talk about how you can deploy your own private LLM on AWS and start playing with it.
Ways to Deploy and Use Your LLM on AWS
In AWS you can deploy your LLM in different ways. It all comes down to the level of customisation the user needs, and to how fast the model can be deployed and used. I will go through each one of them, ordered by speed of execution and level of customisation of the solution.
Amazon Q Business
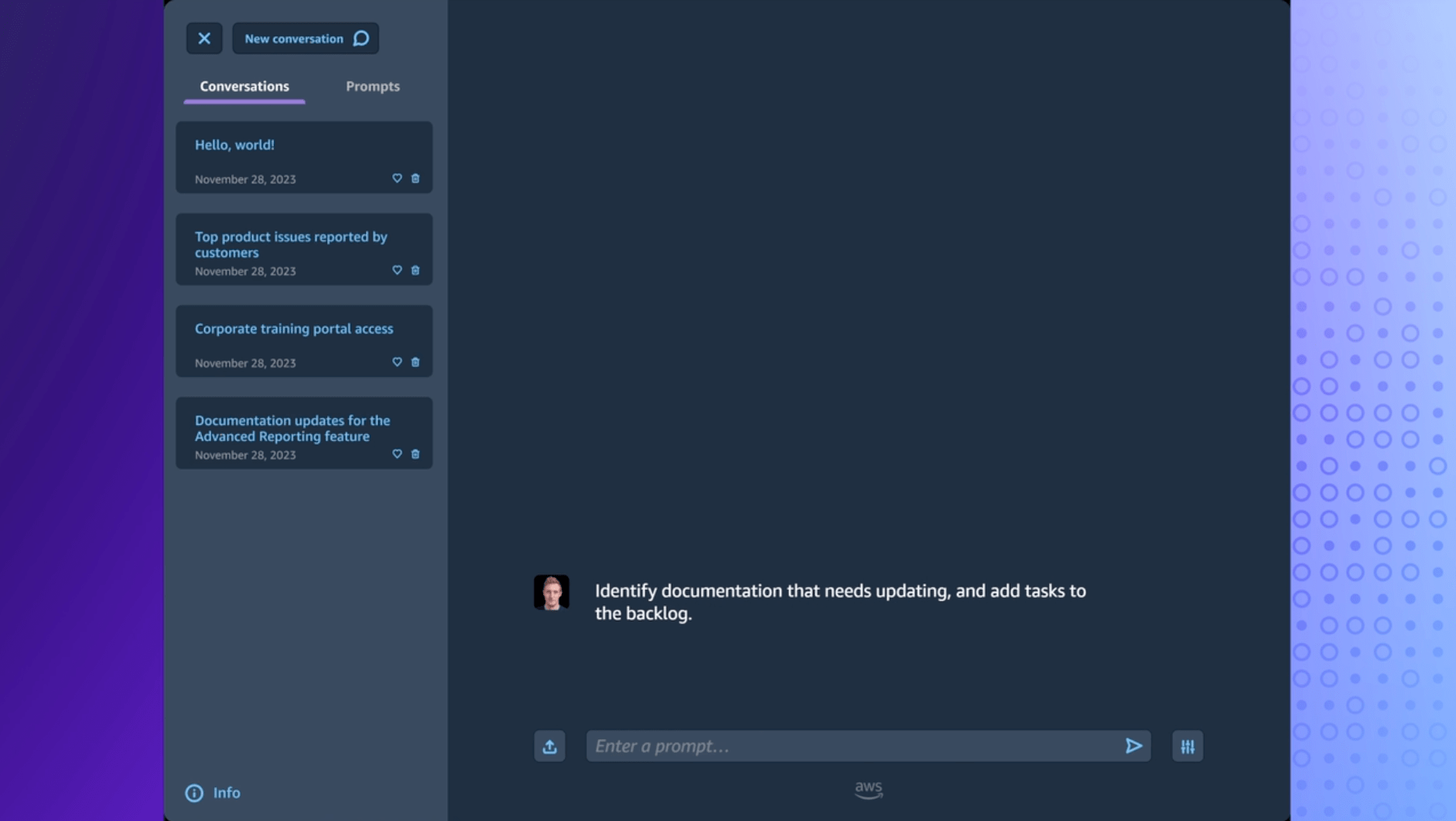
First, if you are only interested in quickly fire up an LLM then Amazon Q Business is what you are looking for.
Currently in preview in the US, Amazon Q is marketing itself as an LLM for the workplace. The main aim is to get things done in a more efficient way in your business by using an LLM.
Amazon Q aim is to quickly deploy a chat-style LLM with a plug-and-play UI (like chatGPT). The user can then improve it. They can do this by using related documents with RAG (Retrieval Augmented Generation) techniques. These will help build context for the model.
If you just want to consume the results of an LLM quickly you can use either Q or Bedrock. The main difference between the two is the fact that with Bedrock you can choose the model
Amazon Bedrock
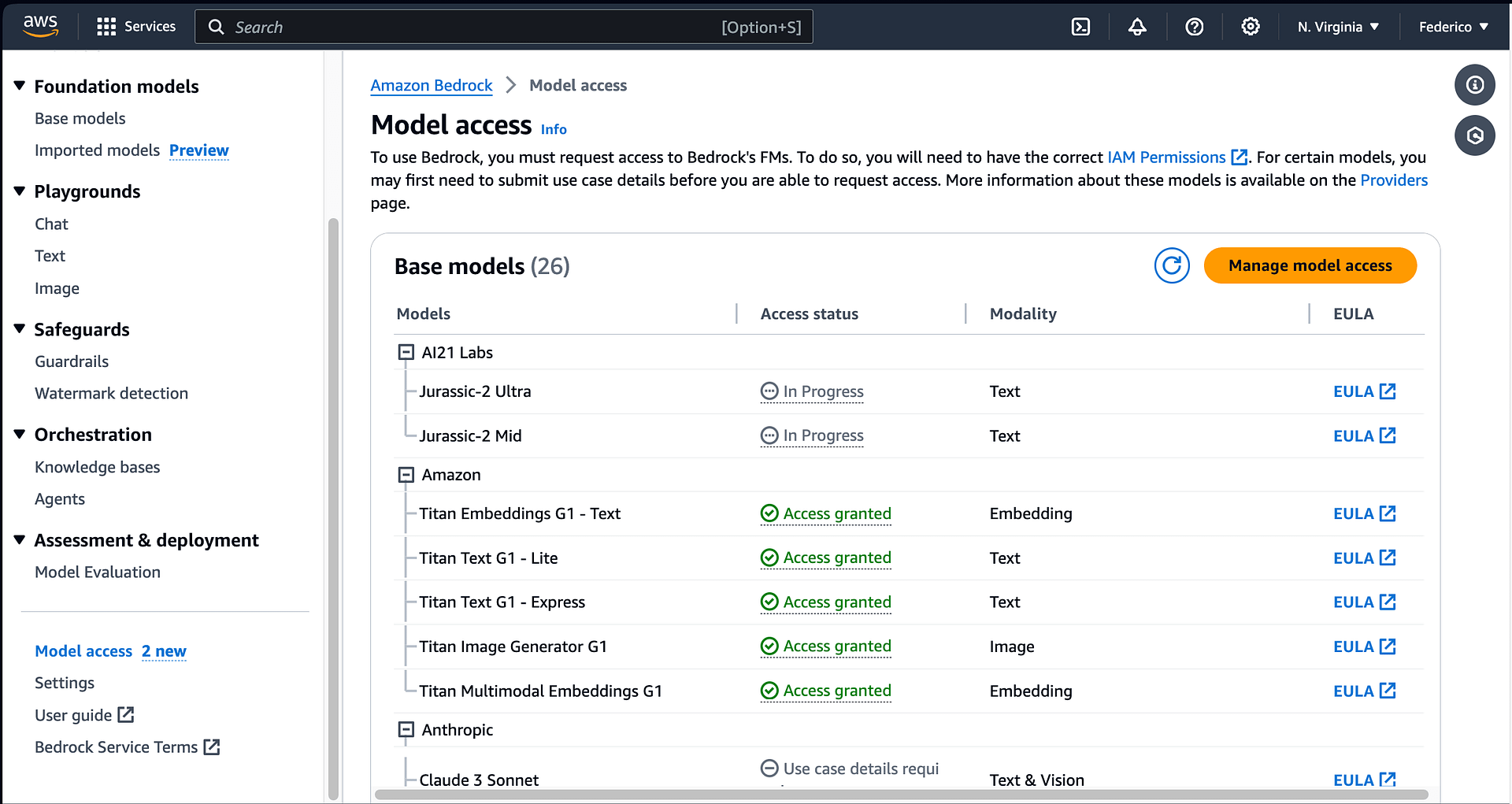
Next, let’s talk about Amazon Bedrock. This service gives you a bit more flexibility than Q. Furthermore, you can choose from a plethora of foundations models. At the time of writing the LLMs currently available are:
- AI21 Labs
- Jurassic-2 Ultra
- Jurassic-2 Mid
- Amazon
- Titan Embeddings G1 – Text
- Titan Text G1 – Lite
- Titan Text G1 – Express
- Titan Image Generator G1
- Titan Multimodal Embeddings G1
- Anthropic
- Claude 3 Sonnet
- Claude 3 Haiku
- Claude
- Claude Instant
- Cohere
- Embed English
- Embed Multilingual
- Command
- Command Light
- Meta
- Llama 3 8B Instruct
- Llama 3 70B Instruct
- Llama 2 Chat 13B
- Llama 2 Chat 70B
- Llama 2 13B
- Llama 2 70B
- Mistral AI
- Mistral 7B Instruct
- Mixtral 8x7B Instruct
- Mistral Large
- Stability AI
- SDXL 0.8
- SDXL 1.0
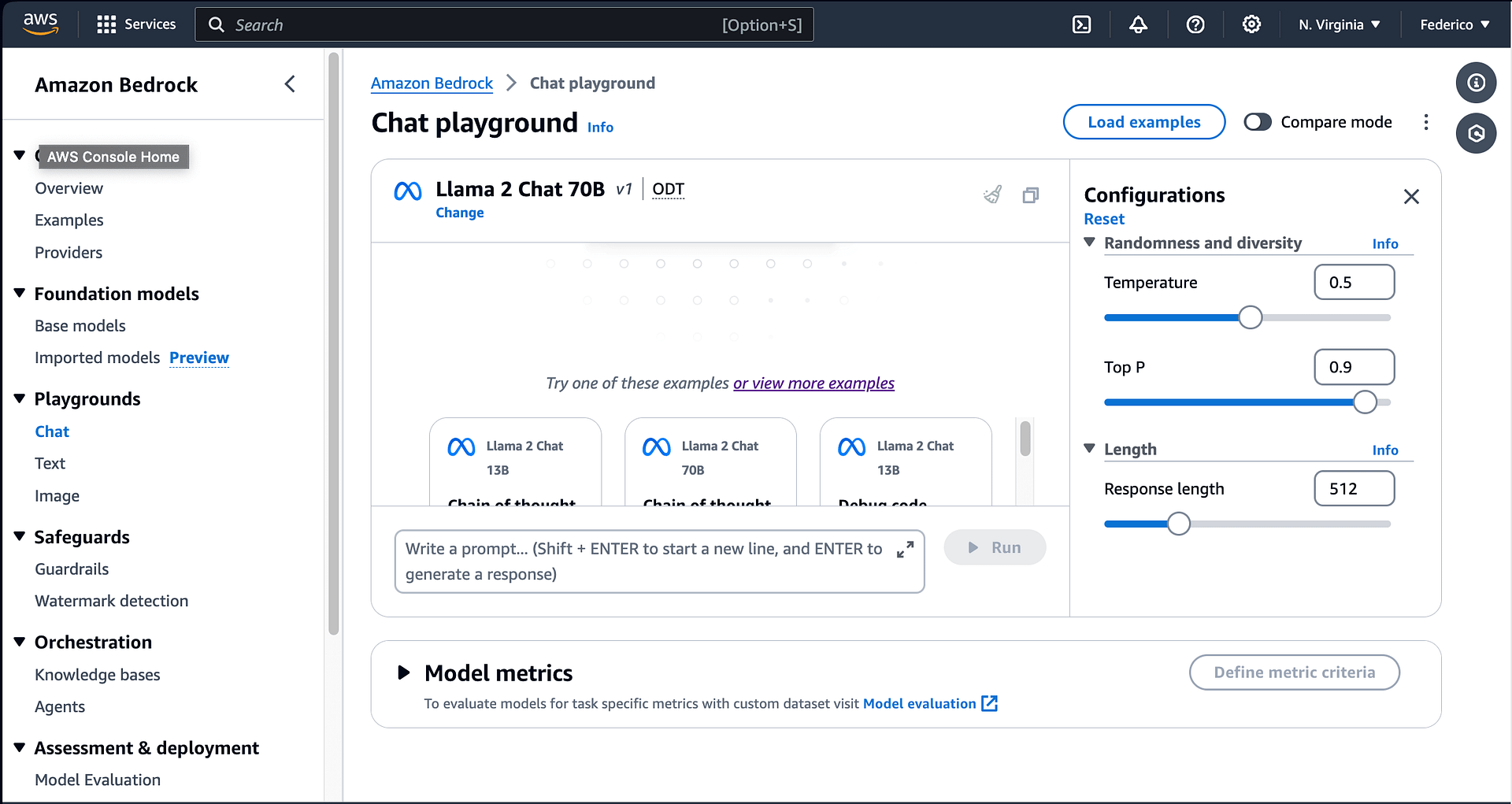
You can use Amazon Bedrock in two ways. You can test the models in the playground first. Also, you have a side-by-side mode where, given a certain prompt, you can compare the output of two models at a time.
Now, you would argue that these models are all available to download. Then, what’s the advantage of using this service? The clear gain here is not taking care of the infrastructure. With Amazon Bedrock, you don’t have to choose the instance type or any configurations. It’s all taken care of for you.
Amazon Sagemaker
Finally, let’s focus on the method. It gives you the most customisation and options. If your use case needs great accuracy and laser-focused context, this is your best choice.
This option lets you spin up your own endpoint. Therefore, you can choose the foundation model, get the settings for your instance, and then decide to fine-tune or retrain it. You can start from scratch or get some guidance using one of the pre-made notebooks available in Jumpstart.
Just giving my two cents here. I would think very carefully before going through this road. Implementing all this requires a lot of time and might prove quite expensive. Also, from my experience, spending more time to get the prompt right might be all it takes to improve your model.
The Use Case: Testing LLMs For Text Classification
The use case for the model evaluation is a text classification problem. I sampled 100 labeled articles. The binary label indicates whether the article is about a topic or not.
This task is currently done manually. So, any automation that could speed it up is greatly appreciated. The idea is to understand how good LLMs have become at doing text classification tasks by only receiving brief instructions.
I went through the different LLMs and found two of them to shortlist: Llama 3 70B and Claude 3 Sonnet. What follows is a comparison of their performance.
Quick Setup
To use the foundation models in Bedrock, you need to ensure that you’ve enabled and consented to them. Then, via the Model access panel, you can select all the ones you are interested in using.
The refined prompt I ended up using is the following:
Act as my article reviewer. I am giving you the text of a blog post enclosed by triple quotes. You need to answer with a binary variable that is 1 if the article is about a Data Science topic, 0 otherwise.
To give you some context I define a Data Science as the study of the extraction of knowledge from data. Data Science uses techniques from many fields, including signal processing, mathematics, probability, machine learning, computer programming, statistics, data engineering, pattern matching, and data visualization, with the goal of extracting useful knowledge from the data. With computer systems able to handle more data, big data is an important aspect of data science.
The answer needs to be a JSON file using this format:
{
'url': 'http://www.urlofthearticle.com',
'about_ds': 1
}
Here's the body of the article: """
Body of the article goes here
"""
The Results
After playing a bit with both the models I figured out that there was a clear winner. Claude 3 Sonnet was more consistent and reliable in getting the format right. It also predicted with more accuracy whether the article was about data science or not.
In the context of my PoC I only used the playground part of Bedrock and annotated the results in a worksheet. Once you are happy with the model and its parameters, you can use the Bedrock SDK in Python to streamline the process. You can then ingest the article body, give the prompt to the model, and get the answer.
The accuracy I was able to get was 77%, which is great if you think that this only took me half a day to set up!
If you are interested in more articles about LLM, have a look at this article where I explore how to setup PrivateGPT using an EC2 instance.
