
Introduction
Depuis l’introduction des Large Language Models, j’ai été intrigué à l’idée d’expérimenter avec et j’étais préoccupé par leur intégration potentielle dans les processus de documentation et de récupération d’informations de l’entreprise. La principale préoccupation est, bien sûr, de s’assurer que les données internes restent privées et qu’elles ne deviennent pas partie des sources de données utilisées pour entraîner le chatGPT d’OpenAI.
J’ai alors été attiré par un article de PyCoach, qui mentionnait un projet d’Iván Martínez. Le point principal du projet est de créer un LLM ouvert et gratuit, particulierment concerné par la confidentialité. Vous pouvez trouver le GitHub repo ici.
J’ai été tellement inspiré que j’ai décidé de créer mon propre Large Language Model (LLM) privé, afin de traiter et ingérer des documents de façon sécurisé.
J’ai d’abord essayé de l’installer sur mon ordinateur portable, mais j’ai rapidement réalisé que mon laptop n’avait pas les spécifications nécessaires pour exécuter le LLM localement, donc j’ai décidé de l’installer sur mon compte AWS, en utilisant une instance EC2. Voici les étapes logiques que vous devez suivre pour faire repeter l’operation.
1. Création d’une instance EC2
Commençons par visiter le site web de AWS et accéder à la page du service EC2.
Maintenant on va créer une nouvelle instance en utilisant une image Ubuntu 22.04.
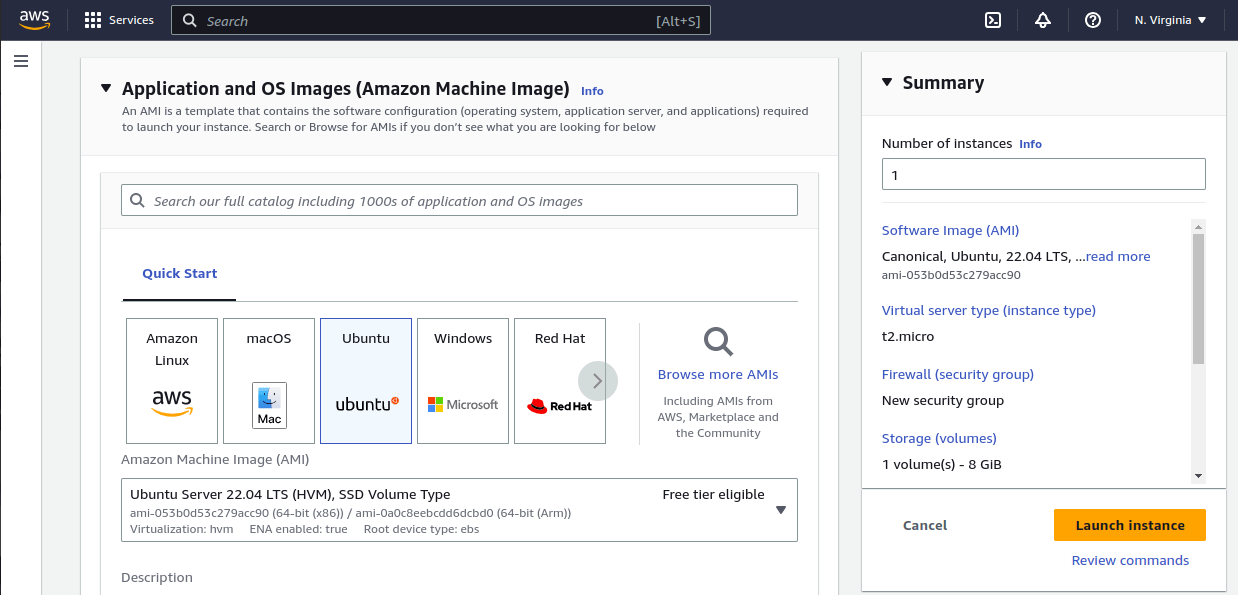
Assurez-vous maintenant que vous avez suffisamment d’espace libre sur l’instance (je l’ai configuré actuellement à 30 Go).
Si vous avez des doutes, vous pouvez vérifier l’espace restant sur la machine en utilisant cette commande:
df -BM2. Configuration des Paires de Clés
Créez une nouvelle paire de clés, téléchargez le fichier .pem et stockez-le dans un endroit sûr.
Changez les permissions du fichier de clé en utilisant cette commande
chmod 400 ~/Documents/aws/privateGPT.pemSinon, vous ne pourrez pas vous connecter car EC2 refusera la connexion en se plaignant que les permissions sont trop ouvertes. Maintenant, vous devriez pouvoir vous connecter en SSH à la machine que vous venez de créer en tapant la commande:
ssh -i ~/path/to/privateGPT.pem [email protected]3. Vérification de la compatibilité AVX/AVX2
Le principal problème que j’ai trouvé en exécutant une version locale de privateGPT était la compatibilité AVX/AVX2 (apparemment, j’ai un ordinateur portable bien vieux, haha).
Ce n’est pas un problème sur EC2. Si vous voulez vérifier que c’est le cas, vous pouvez utiliser la commande:
grep avx /proc/cpuinfo4. Installation de Python 3.10 et pip
Python 3.10 est essentiel pour faire fonctionner privateGPT.
Tout d’abord, pour vous assurer que votre système est mis à jour et que les paquets nécessaires sont installés, tapez la commande suivante :
sudo apt install software-properties-common -yEnsuite, ajoutez le PPA deadsnakes à la liste des sources du gestionnaire de paquets APT comme ci-dessous.
sudo add-apt-repository ppa:deadsnakes/ppaAvec le dépôt deadsnakes ajouté à votre système Ubuntu, téléchargez maintenant Python 3.10 avec la commande unique ci-dessous.
sudo apt install python3.10Enfin, vous pouvez installer pip3
sudo apt install python3-pip5. Configuration de l’Environnement
Vérifions maintenant que git est installé
gitClonez le dépôt privateGPT
git clone https://github.com/imartinez/privateGPT.gitEnsuite, naviguez jusqu’au repo cloné
cd privateGPT/et installez les prérequis en utilisant pip
pip3 install -r requirements.txt6. Téléchargement du LLM
Changez le nom du fichier de variables d’environnement en utilisant la commande mv
mv example.env .envCréez un dossier qui contiendra le LLM
mkdir models
cd models/Et maintenant utilisez wget pour télécharger le fichier LLM actuel (cela peut prendre un certain temps, le fichier fait environ 3,5 Go)
wget https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.binAjout de Documents à la Machine
C’est là que le plaisir commence! Le repo vient avec un fichier exemple qui peut être utilisé immédiatement, mais je suppose que vous ne serez pas intéressé par poser des questions sur le discours sur l’état de l’Union. Donc, vous pouvez d’abord naviguer dans le dossier, puis vous assurer qu’il ne contient aucun fichier en utilisant ces commandes.
cd ../
rm source_documents/*Maintenant, vous pouvez ajouter les fichiers que vous souhaitez utiliser et poser des questions en utilisant SCP. N’oubliez pas que vous devrez également passer le fichier pem en paramètre pour établir une connexion sécurisée avec la machine
scp -i ~/path/to/privateGPT.pem ~/path/to/document.extension [email protected]:~/privateGPT/source_documentsIl est enfin temps de poser des questions sur vos documents !
J’aime le fait que PrivateGPT prend en charge une variété de formats couramment utilisés. Les extensions actuellement supportées sont :
.csv: Fichier CSV,
.docx : Document Word,
.doc : Document Word,
.enex : EverNote,
.eml : Email,
.epub : EPub,
.html : Fichier HTML,
.md : Markdown,
.msg : Message Outlook,
.odt : Texte de Document Ouvert,
.pdf : Format de Document Portable (PDF),
.pptx : Document PowerPoint,
.ppt : Document PowerPoint,
.txt : Fichier texte (UTF-8),
Maintenant, il y a deux commandes clés à retenir ici. La première permettra d’ingérer tout document disponible dans le dossier source_document, créant automatiquement les embeddings pour nous.
cd ~/privateGPT
python ingest.pyLa seconde créera une session interactive où nous pourrons poser des questions sur les documents ingérés
python privateGPT.pyC’est tout ! Vous venez de créer votre propre LLM personnel qui répondra aux questions sur tout document que vous décidez d’ingérer. Maintenant, seul le ciel est la limite.
Comme note finale, il convient de mentionner que ce projet est toujours en cours de développement et que la solution est loin d’être prête pour la production, car elle n’est pas axée sur la performance, mais sur la confidentialité. Obtenir une seule réponse sur un petit document peut effectivement prendre plusieurs minutes.
